
AI & LLM
Building Long-Term memories using hierarchical summarization
Learn how hierarchical summarization builds efficient Long-Term memories by capturing, summarizing, and organizing data for faster context retrieval.

Jim Bennett is the worlds most energetic developer advocate, and head of developer advocacy at Pieces for Developers, focusing on enabling developers to be more productive by leveraging contextual awareness of not only the code they write, but the content the read and the conversations they have. He’s British, so sounds way smarter than he actually is, and lives in the Pacific North West of the USA. In the past he’s lived in 4 continents working as a developer in the mobile, desktop, and scientific space. He's spoken at conferences and events all around the globe, organized meetup groups and communities, and written books on mobile development and IoT.
He also hates and is allergic to cats, but has a 12-year-old who loves cats, so he has 2 cats.
Learn how hierarchical summarization builds efficient Long-Term memories by capturing, summarizing, and organizing data for faster context retrieval.
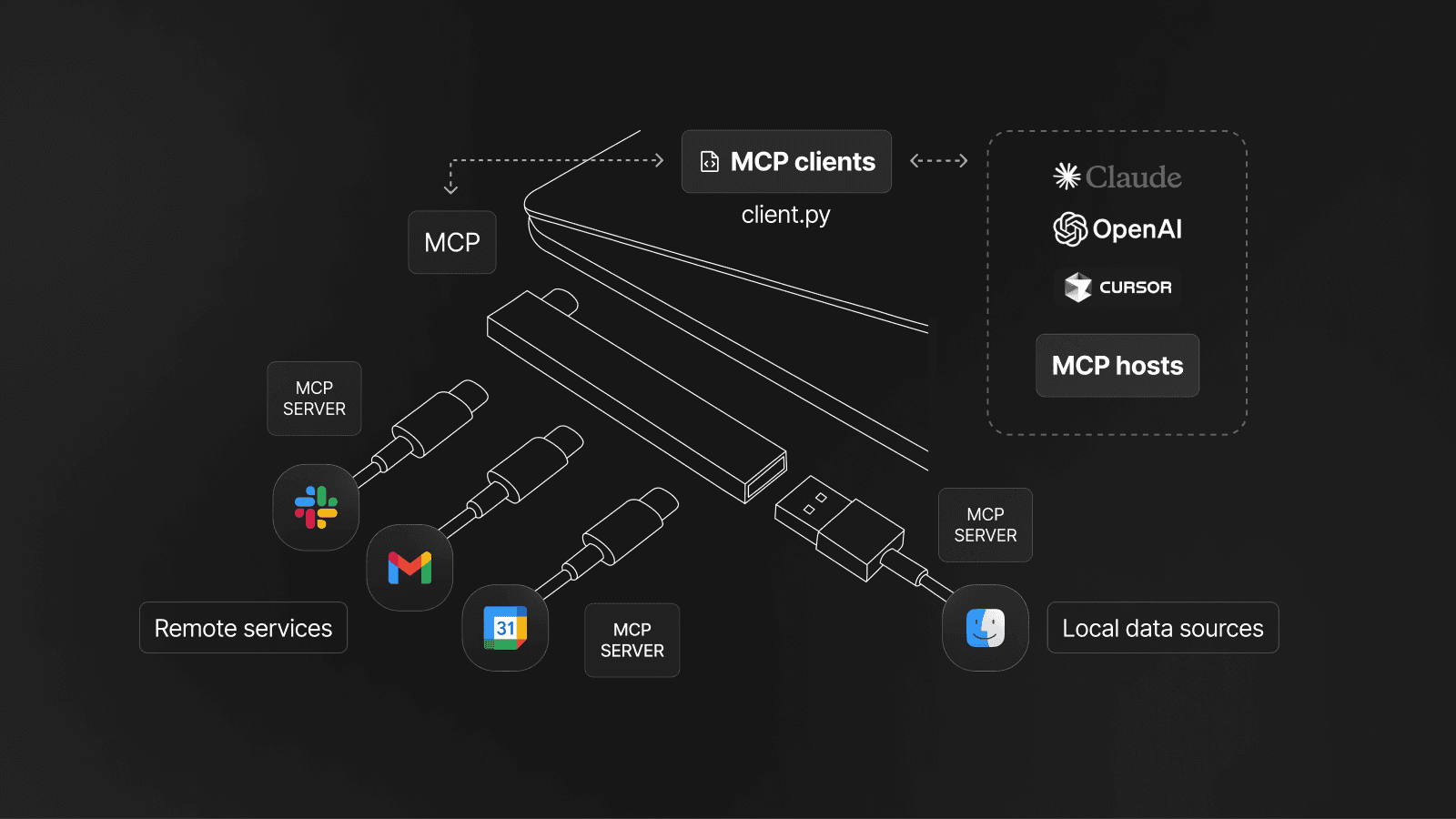
At Pieces we’ve just announced our new MCP server, allowing you to interact with your Pieces Long-Term Memory from any MCP client, such as Cursor or GitHub Copilot.

Amir Schvatz, investor at Dark Mode, shares insights on AI, developer platforms, and the rise of "PM Coding" in software creation.

Discover how Model Context Protocol (MCP) helped our team streamline workflows, reduce development time, and increase productivity, all while doing more with less

50 LLMs benchmarked for real dev tasks: see how IBM outperformed OpenAI and what it means for the future of AI tooling.

AI in observability: What works, what doesn’t. Phillip Carter shares where humans still lead and where AI fits in.

Explore social robots, emotional AI, and long-term memory with David Packman, co-founder of Packabby Robotics.

Shaundai Person on engineering culture, AI for productivity, and the "Shaundai Hierarchy of Needs" for developers!

Learn how Toolhouse simplifies AI, Groq’s impact, and the future of affordable AI beyond the US. Tune in now!

Forget everything else — Long-Term Memory is the key to smarter, more efficient AI. Discover how it revolutionizes learning, recall, and decision-making.

Off-the-shelf copilots are obsolete! Build a custom AI copilot powered by your own data using Pieces AI for smarter, more personalized automation.

Discover what Small Language Models (SLMs) are and how they can revolutionize AI adoption. Learn how SLMs offer efficiency, privacy, and cost-effective AI solutions for businesses.

Language models, both large and small, have their size measured in parameters. The big, cloud models, like GPT-4o use trillions of parameters, whereas smaller models you can run locally have billions of parameters.

Discover the best LLM for coding - whether you’re generating code or just asking questions, understanding cloud vs local LLMs can make you more effective.

Enable offline AI with on-device LLMs, enhancing your productivity in privacy-focused environments.

Pieces has added more local models to power the copilot and long term memory including Qwen coder and Phi-4

Combine Pieces and GitHub Copilot to build a powerful workflow with long-term memory and AI assisted coding

Combine Pieces and Cursor for a powerful AI assistant with Long-Term Memory and agentic workflows to boost productivity

Leverage Engineering is a team at OpenAI that dogfoods openai to improve internal processes. Learn more about these types of roles.

Discover 5 powerful prompts for Pieces to enhance your productivity and workflow as a software engineer.

Chat with LLMs offline or in secure environments using Pieces. Seamlessly switch between cloud and local models, now powered by Ollama.

Check out best practices for prompt engineering with AI Copilots. Learn clear and concise prompts, ensuring optimal responses and improved results.

Master LLM prompt engineering with this step-by-step tutorial for developers. Learn techniques to craft effective prompts and optimize AI responses for better results.

LLMs are non-deterministic, so are hard to unit test. Learn how to do so by using one LLM to validate another

Discover how we created a Raspberry Pi-powered confetti cannon demo using Viam robotics and Pieces for developers at FlutterCon.